Exchange Data with SC Navigator
Overview
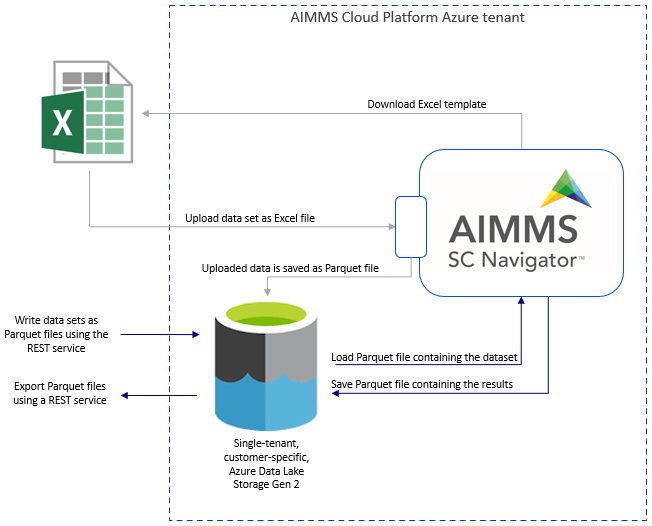
The AIMMS SC Navigator apps require input data from other systems and may export data to other systems, beyond manual file upload into the app. This document describes how to exchange data between your on-premise data systems and the AIMMS SC Navigator apps running on the AIMMS Cloud. In the past, this used to be accomplished through the ‘SC Navigator database’, the (MySQL) database from/to which the AIMMS SC Navigator apps read/write data. Currently, this is achieved through a single-tenant, customer-specific, Azure Data Lake Storage Gen 2 via SAS Tokens. Customers are free to design and implement their solution for exchanging data with this data lake storage, using industry standards and common tools for Azure Data Lake Storage interaction.
Details
The Azure Data Lake Storage Gen 2 in the AIMMS Cloud acts as the decoupling connection point between your data (on-premise or in the cloud) and the SC Navigator applications. At system setup, three Azure file systems are created in the Azure Data Lake:
sc-navigator
sc-navigator-import
sc-navigator-export
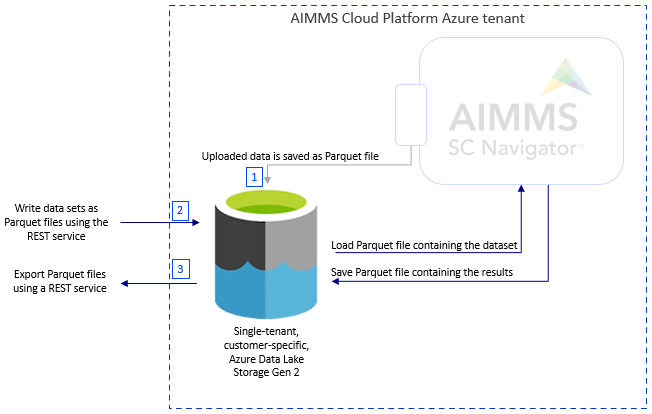
The sc-navigator (item 1 in the figure above) file system is only accessible by the SC Navigator applications and is used to store all relevant data needed for the application.
The sc-navigator-import (item 2 in the figure above) file system is the location where you can create a folder with a set of parquet files which contain an input dataset for the application. Each dataset needs to be located in a separate folder, see below for details (Parquet File Structure).
The sc-navigator-export (item 3 in the figure above) file system is the location where you can find results dataset which are created in the application. The SAS tokens to access these two folders can be generated on the page SAS Tokens in the System Configuration application.
Parquet File Structure
An Excel file with the structure of the parquet files for SC Navigator can be downloaded using the section Download Parquet File Structure. This file contains two sheets:
Parquet Definition
Custom Objectives
The sheet Parquet Definition determines the parquet files which can be created for a dataset. You only need to create files that have data (if you do not have data for a particular file, the file does not need to be created). For instance, if you do not have an inventory model, you do not need to create the file inventory-step.parquet.
The columns in the Parquet Definition sheet describe the name and the structure of the files:
File Name: This is the name of the parquet file.
Attribute: The name of the columns in this parquet file.
Mandatory/Optional: Indicator if this column is mandatory or optional. (In case it also has Key in the name, it means that this is part of the index domain and the combination of key columns must be unique).
Type: This tells if this data value should be of type string, numerical, integer, or binary value.
Description: This explains what the meaning/purpose of this column is.
In the output files, it is possible that the Type in the parquet files is different from what you might expect based on the data. In those cases, the data type in the parquet file is specified like this (BYTE_ARRAY) as part of the type. For instance, you might see “Integer (BYTE_ARRAY)”, meaning the actual data is an integer value, but it will be stored as a “BYTE_ARRAY” in the parquet file.
The structure of the parquet files is very similar to the structure of the Excel file. The main difference is that each sheet in Excel is now an individual parquet file. Therefore, the coloring in this file is similar to the coloring in the Excel template. The main difference is that with the parquet files you need to create an additional file _dataset_info.parquet with information which is normally entered in the User Interface (UI) or generated in the apps.
The sheet “Custom Objectives” contains the contents of the parquet file custom-objective.parquet. The file custom-objective.parquet determines the custom objectives which are available in the model, together with some needed information for those custom objectives. This influences what custom objectives attributes will be read in when the parquet files are read. So, if the data from sheet “Custom Objectives” is not in the file custom-objective.parquet, then the custom objective data is not read in from the other parquet files.