Importing data from Alteryx into SC Navigator
This article describes an example on how to use Alteryx to transform multiple sheets from an Excel-file into parquet-files and push these to the Azure Data Lake Storage of the AIMMS Cloud.
You can download the example Alteryx workflow here and use it directly in Alteryx.
Configuration in Alteryx
You can download the Alteryx workflow from the link in the first paragraph.
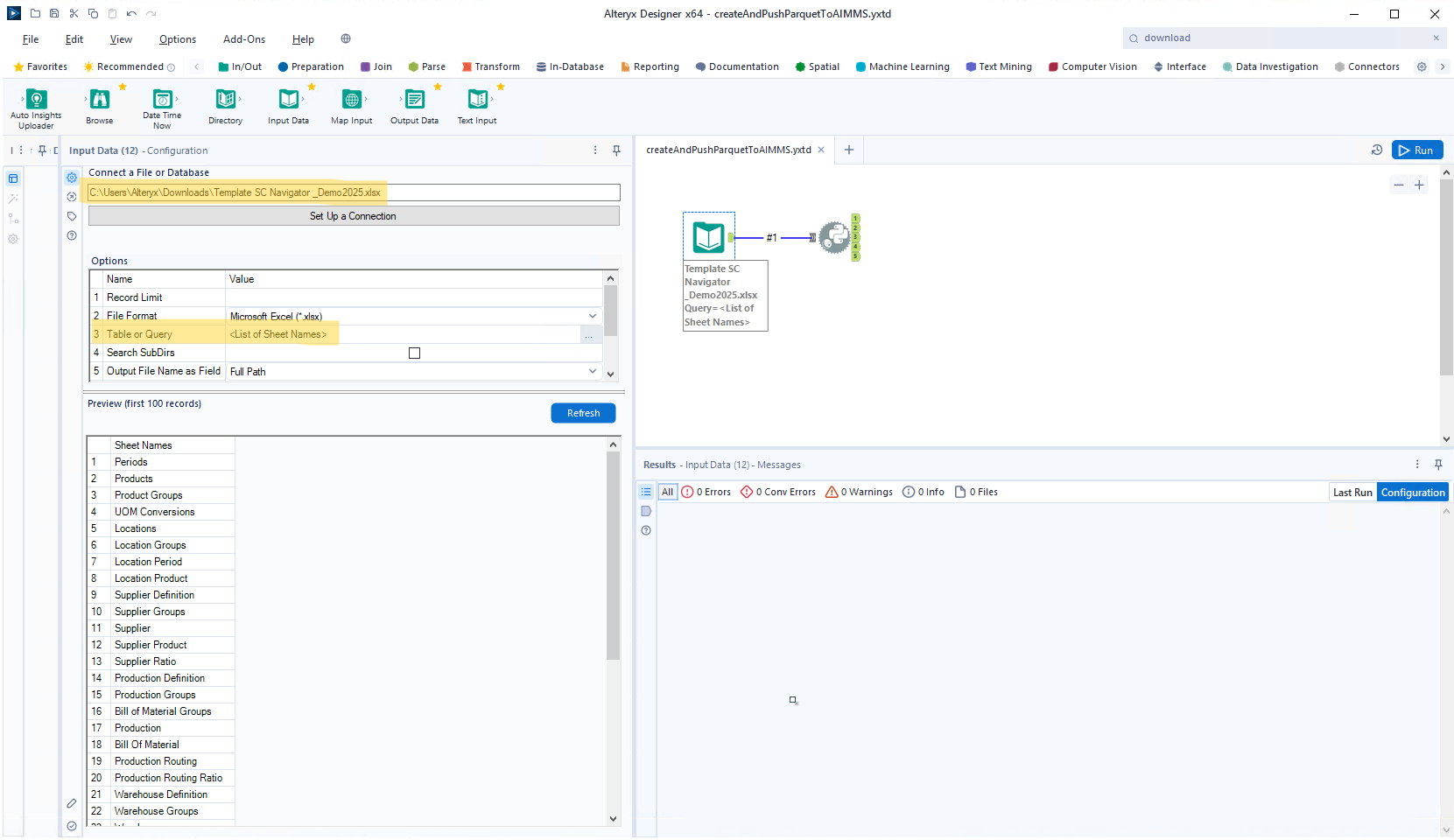
In the first step of the Alteryx workflow, you’ll need to define your input-file and make sure you select ‘<List of Sheet Names>’ for ‘Table or Query’:
In the second step the template covers a Python-script integrated through a Jupyter notebook in which the conversion of the data happens and the parquet-files are being pushed to the ADLS.
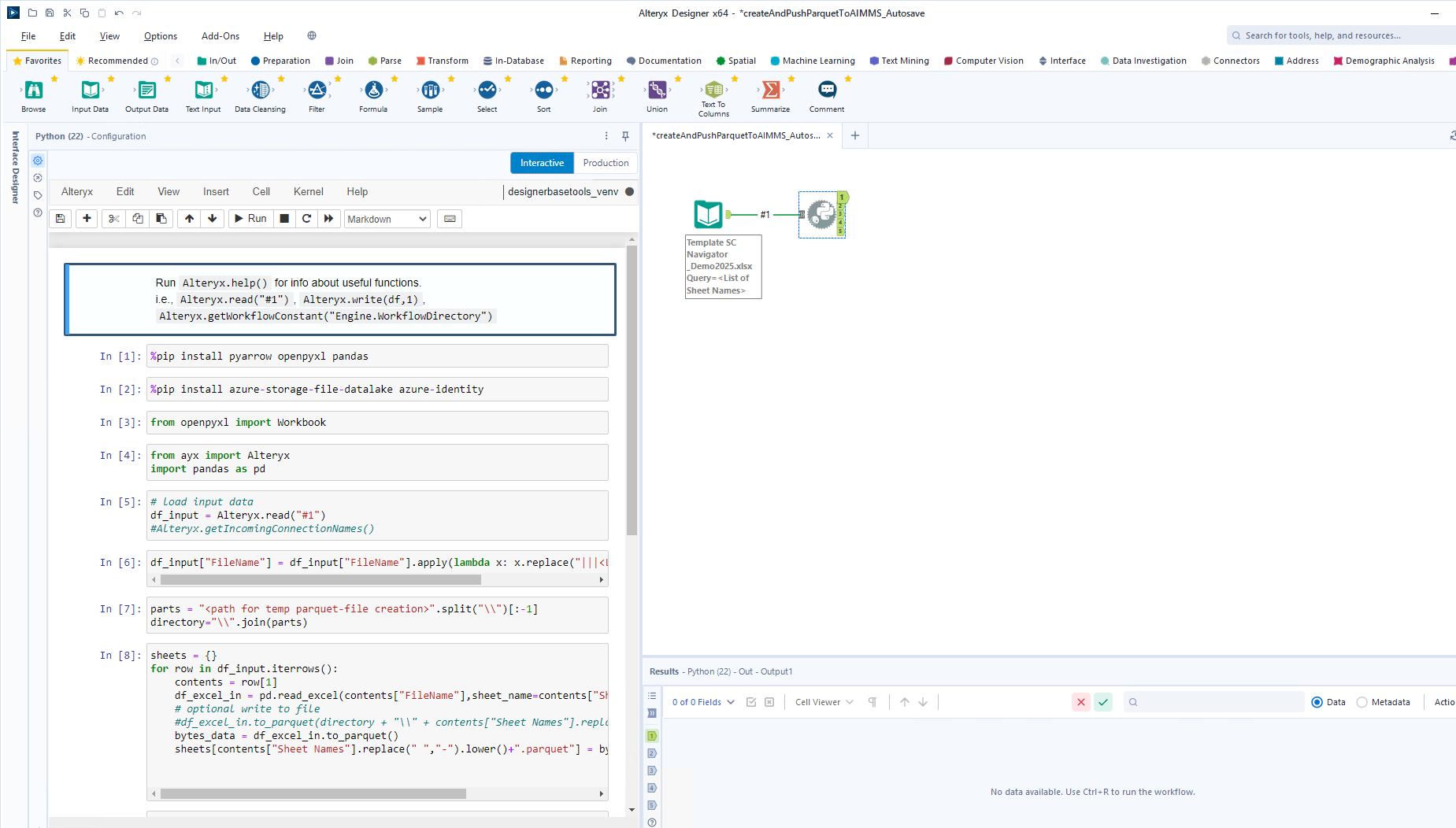
In the downloaded example you’ll need to replace the ‘TODO’-items with your own variables. Below we will describe the code fragments. You will be using Python packages for the connection to the ADLS and some wrangling of the data. First these need to be installed:
1%pip install pyarrow openpyxl pandas
2%pip install azure-storage-file-datalake azure-identity
3from openpyxl import Workbook
4from ayx import Alteryx
5import pandas as pd
In the first step in the workflow in Alteryx a full Excel-workbook is being loaded. We load this input in the next steps and iterate through the worksheets and create a parquet-file based on each worksheet:
1# load input data
2df_input = Alteryx.read("#1")
3#Alteryx.getIncomingConnectionNames()
4
5df_input["FileName"] = df_input["FileName"].apply(lambda x: x.replace("|||<List of Sheet Names>", ""))
6
7parts = "<path for temp parquet-file creation>".split("\\")
8directory="\\".join(parts)
9
10sheets = {}
11for row in df_input.iterrows():
12 contents = row[1]
13 df_excel_in = pd.read_excel(contents["FileName"],sheet_name=contents["Sheet Names"])
14 # optional write to file
15 #df_excel_in.to_parquet(directory + "\\" + contents["Sheet Names"].replace(" ","-").lower()+".parquet")
16 bytes_data = df_excel_in.to_parquet()
17 sheets[contents["Sheet Names"].replace(" ","-").lower()+".parquet"] = bytes_data
In the above code fragment you will need to define a path (for parts) in which the parquet-files can be generated and stored temporarily:
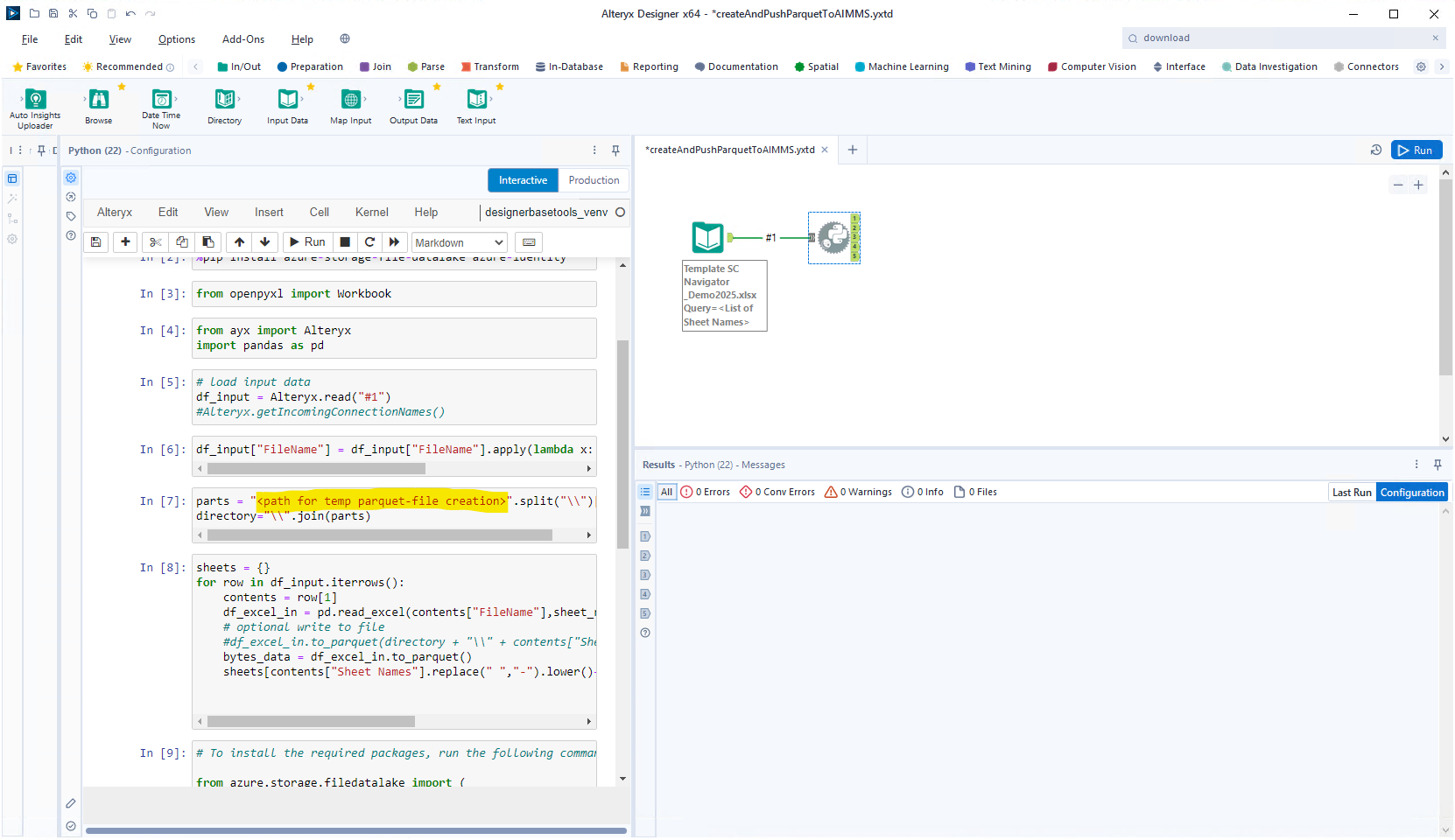
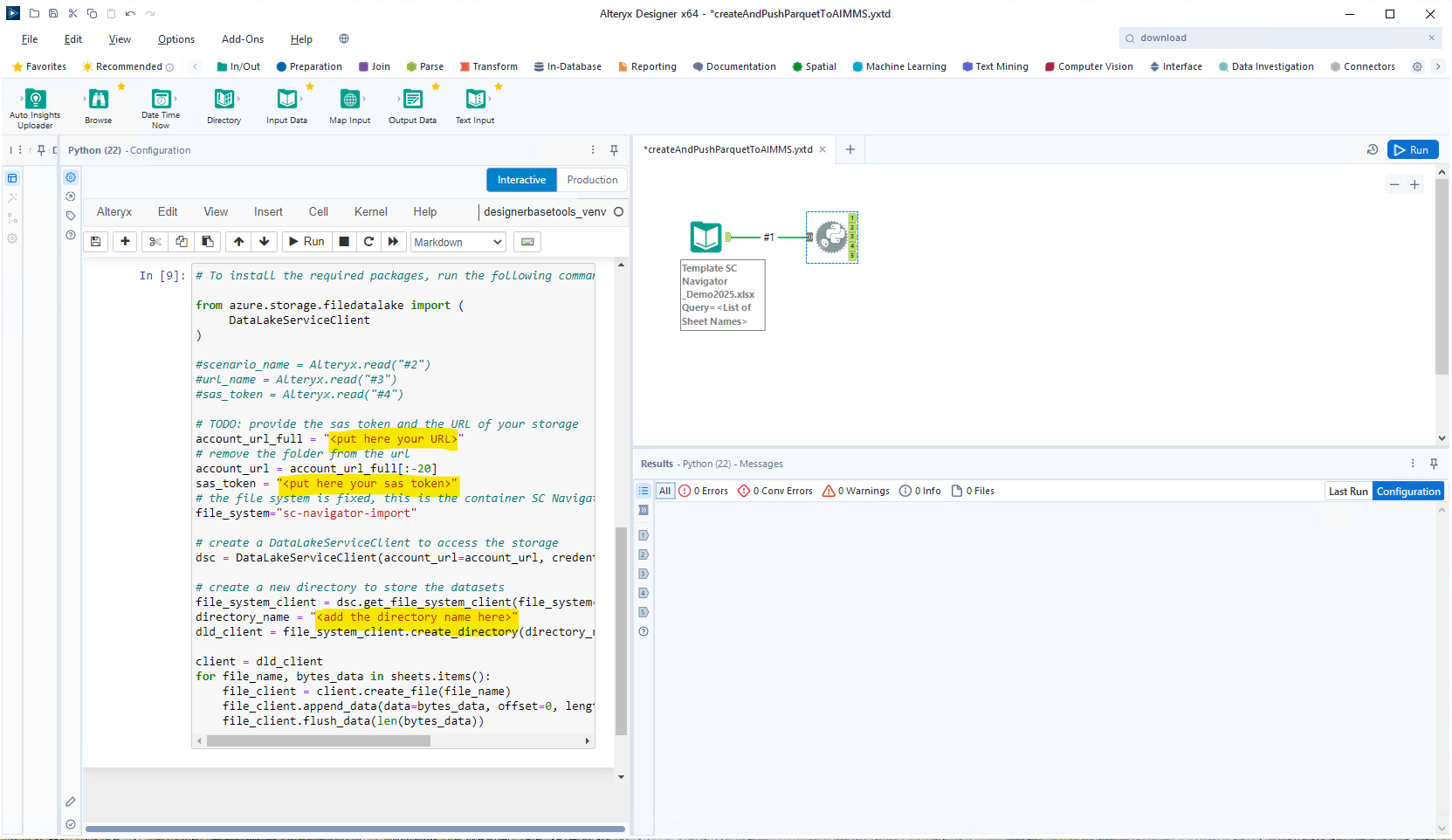
Now we make the connection to the ADLS, where you’ll need to define some parameters:
1# To install the required packages, run the following command in your terminal or Jupyter Notebook:
2from azure.storage.filedatalake import (
3 DataLakeServiceClient
4 )
5
6# TODO: provide the sas token and the URL of your storage
7account_url_full = "<put here your URL>"
8# remove the folder from the url
9account_url = account_url_full[:-20]
10sas_token = "<put here your sas token>"
11# the file system is fixed, this is the container SC Navigator will write its results
12file_system="sc-navigator-import"
13
14# create a DataLakeServiceClient to access the storage
15dsc = DataLakeServiceClient(account_url=account_url, credential=sas_token)
16
17# create a new directory to store the datasets
18file_system_client = dsc.get_file_system_client(file_system=file_system)
19directory_name = "<add the directory name here>"
20dld_client = file_system_client.create_directory(directory_name)
21
22client = dld_client
23for file_name, bytes_data in sheets.items():
24 file_client = client.create_file(file_name)
25 file_client.append_data(data=bytes_data, offset=0, length=len(bytes_data))
26 file_client.flush_data(len(bytes_data))
An example of the value expected at account_url_full is
https://cloudName.dfs.core.windows.net/sc-navigator-export.For the sas_token parameter you should only paste the SAS-token itself.
The directory name is up to you to decide.
After adding the details and running the workflow, your parquet-files should be pushed onto the ADLS, in a folder for which you’ve defined the directory name. Now on the AIMMS Cloud you can open the System Configuration app (or ask your admin to do this) and push the rebuild overview button on the File System Management tab. If you now open SC Navigator you should see that your dataset is added to the overview.